19.May.2024
要坚信自己的代码最好
之前说过, 部门的老领导高升了, 他手里的代码传给了我来维护. 本来想着给我就给我呗, 应该也用不上. 结果没想到, 这才没多久, 他们就催我用遗产代码跑数据.
🤔行吧, 领导说了算, 于是我就打算对云遗产(代码)review下, 怕有什么没注意到的地方留坑.
这代码完成的功能还是很伟大的, 但不看不知道, 嘶… 代码本身炸裂.
-
变量名能简单就简单, 就像我在memos吐槽的一样, 连续开了5个文件, 起名一点不犹豫, f1-f5, 简直是自带混淆.
-
他是真不爱写注释啊, 洋洋洒洒一大片, 一点注释都没有. 就不提若干年了, 这代码放半年再回来看都是谜之神秘.
-
功能需要读取文本数据, 在代码里倒是给读取文件的路径留出了变量方便使用时修改. 但你不能…不能在实际处理的地方还
tm用之前变量的默认固定路径来进行文件分类吧, 这是人能干的? -
大篇幅相似雷同的sql语句放一起, 如果增加了新的表就要自己复制粘贴修改一遍…emm, 不说麻烦不麻烦了, 就现有的复制粘贴sql里都能看见有忘记改的地方, 咱就不能用代码生成嘛.
-
功能类似的从库表导数据的代码也是一样, 复制到不同文件然后修改细节…我一开始特别担心不同的地方漏过了, 还一个个用代码比对了, 万一修改连接啥的太可怕了.
-
云遗产是一系列的文本处理代码集, 倒是每个功能分了不同的文件夹, 但是他好几个功能混在一个文件夹里, 大文件夹套小文件夹, 每个文件夹都有一层放数据的位置. 好好好, 你厉害.
-
数据跟代码混在一起存放, 几百个GB的玩意, 拆不出来代码也不好上git, 这要哪天硬盘螺旋升天了, 这宝贝代码岂不是…
还有更多的, 就不一一说了, 总之这个人的代码习惯是真差劲儿啊!!! 我立马就新建了一个文件夹(啊, 不是, 新建了项目), 打算照着功能重新实现一个.
代码主要是对源库数据采集, 旧数据更新, 新数据二次加工后导入项目数据库.
源库数据导出
代码需要对八九种不同的源库地址里的数据库进行分类导出到固定格式(r格式文本)的文本中. 每种数据导出代码有相似的部分(对源库连接处理/固定文本格式处理), 但也有不同的(导出时会对数据进行简单选择, 加工). 但并不是说八九种库就写在八九个不同的代码里, 由于需求的不同, 每个库里少的有3-4个不同的处理方法取不同表数据, 多的那种有十几个.
遗产中对于这块的处理方式就是每种数据的代码都是复制粘贴过去, 然后在不同处进行细微调整处理. 但这一旦有什么通用的需要修改, 比如源库处理方法/库连接地址要修改, 那就得一一改, 而且还容易粗心造成问题.
最容易想到的是把共性的代码部分写成基础方法, 然后每个表/表集合import基础方法/继承调用. 但总觉得这种方法把这件小事变得很复杂, 有杀鸡焉用牛刀之感.
把配置的参数从外部引进倒是个挺好的解决办法, 但是刨去配置后, 剩下的代码其实共性蛮大的. 况且一个库下不同表/表集合的处理有相同的部分, 全部都拉出去感觉不够简洁, 从复制粘贴代码变成了大部分配置信息的复制+少部分不同, 不喜欢.
犹豫很久(主要是新领导/销售/产品催催催催催)😑, 最后还是决定用配置文件方式解决.
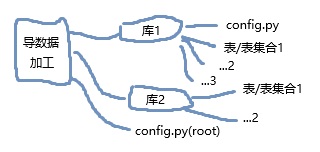
我用py文件存放配置信息, 每个有效的配置信息都会视为一个数据导出任务(一个表/表集合). 同一个库的任务放在一个文件夹内, 若文件夹内含有config.py(也可以没有), 则被视为这个库下所有任务的通用配置. 在整体配置信息root还有一个全局配置信息. 我会扫描提供的配置路径, 自动生成任务.
在一个任务发起后, 会根据:任务配置 > 库配置(如果存在) > root配置(优先级:高 → 低)的顺序加载配置信息, 同一个配置项若存在高优先级的, 则不加载低优先级. 通过此方法生成该任务的配置内容, 进行数据拉取.
这样的优点是, 最少的代码以及配置内容, 还方便对基础方法修改, 增加/删除配置信息. 由于是用py作为配置信息, 源数据存储前的加工方法也被我放在配置中.
文本数据加工
-
r格式文本解析
公司数据库用的是自研数据库, 它支持一种r格式的文本追加数据/列更新. 遗产中, 用非常传统的方式, 手撸字符串来对r格式进行解析和生成. 这可太不优雅了, 我写了个r解析的底层方法来对r格式进行支持. 读取文件后会返回一个迭代器, 里面是字典格式的行数据, 你还可以通过传入模板对数据进行格式化. 写数据的时候也同样, 这样就会很方便.
-
代码/文件夹结构优化
之前文件夹存放的很乱, 各种功能混在一起. 这一次在新建文件夹的过程中, 我把他们重新按照功能分类, 放在了对应的文件夹中. 遗产中我吐槽的代码都按照原有功能重写了, 有共性的基础处理方法也进行了封装. 这过程中, 还发现了不少遗留bug. 把代码和数据做了有效的拆解, 拆解后的代码也顺利上了内部git. 当然, 在花大精力读懂代码之后, 最最最重要的是, 补上注释.
-
sql语句生成
实在难以苟同复制修改sql的方式, 我把sql按照功能写成了不同的模板, 然后在代码里, 套用模板进行生成sql. 这样麻麻就再也不用担心我改忘了弄出什么奇怪的数据了.
结尾吐槽
单纯是有点憋不住, 又要长脑子了.
- 导出数据的过程中, 连接特别不稳定, 特别是下班的时候, 就好像源库它也不加班一样.
- 因为后期要更新数据, 所以把项目数据库拖到本地来更新, 防止数据搞坏了没有退路了. 但是项目数据库特别大: 2.2TB, 放不下!!! 没办法, 放在了好几台内网测试机上做数据.
- 有一些多年继承的数据, 里面混杂了好几种的数据格式, 遗产没有对数据进行清洗, 反而是写了多种的处理方法. 一开始我嘲笑并去掉它, 后来被教育了, 我怒而把数据全清洗了. 💢
- 让他们催吧, 反正你不能着急, 这活丫的它不是几天能干完的. 导数据就导了一周半, 加班没用的, 真的!
经过我的一顿爆改把新建文件夹填满后, 终于舒坦了, 这种快感不亚于通关了某个RPG. 我的代码不一定完美, 可能在大佬面前仍有问题. 但🙃野花哪有家花香, 永远要坚信自己的代码最好.
好几周没写博客了, 这就是我暴躁的原因, 愿我再也不用接他人的遗产代码了.
comments 🙊🙉🙈